Was that result because the engine is good, or because it got lucky?
That’s the entire point of forward-testing. You take your “finished” system and try, in six different ways, to break it. If it survives all six, you have earned the right to trust it. If any of them crack it open, you go back to the lab.
Why This Test Matters
This is the most basic sanity check. You split history in two. You “train” your system on the first chunk. Then you test it on the second chunk, which the system has never seen.
If the system was overfit (meaning: tuned so tightly to the training data that it memorized the specific bumps and wiggles), it will fall apart on the test chunk. Numbers drop, Sharpe tanks, drawdowns balloon.
The fear: you built something that only looks good in the past because you accidentally tuned it to the past.
What “Good” Looks Like
Test Sharpe within ~20% of training Sharpe. A modest drop is totally normal.. markets change, the test period always has its own character.
The Results
Train (2003–2015): Sharpe 0.754, Annual Return 8.29%, Max DD −16.22%
Test (2016–2026): Sharpe 1.219, Annual Return 13.43%, Max DD −12.44%
Change: Sharpe +61.8%, Return +61.9%, Max DD actually smaller in the test period
The test period didn’t just survive.. it outperformed the training period on every single metric. Scary good results.
What To Take Away
The engine isn’t curve-fit to 2003–2015. If anything, it handles the modern regime (post-2016: COVID, 2022 rate shock, the 2025 tariff scare) better than the training era. That’s the opposite of what an overfit system looks like.
One honest caveat: this is a train/test holdout, not a rolling walk-forward. V5’s parameters were frozen by a prior parameter sweep, so re-tuning in each window wouldn’t add information here. The point of this test was specifically to confirm the frozen parameters don’t blow up OOS. They don’t.
Sidenote: While writing this article I decided to actually wire up a rolling walk-forward test as well. The short conclusion? All three soft gates passed.
This shows 21 paired 1-year comparisons plus 19 rolling 3-year windows. Both passing together means the OOS robustness isn't an artifact of where the split point happened to land.
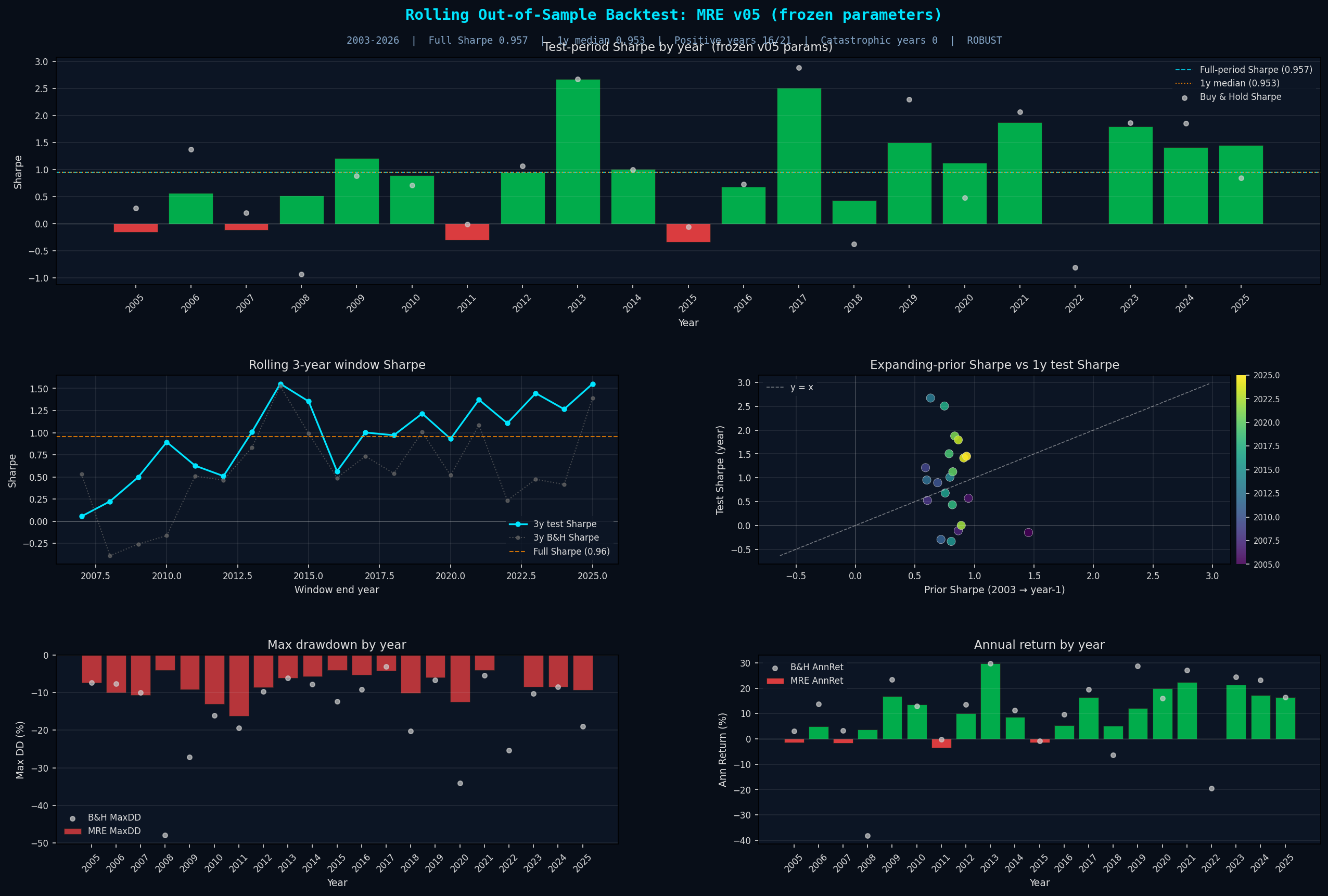
Why This Test Matters
Your system has knobs. My system has a lot of knobs. Every knob is a choice, and every choice is a potential overfit. If your result depends on minVotes being exactly 12 and everything explodes at 11 or 13, you didn’t find an edge.. back to the drawing board with you!
A real edge is smooth. If you wiggle every parameter by ±1 or ±2 around its “optimal” value, the Sharpe should degrade gracefully, not cliff-fall. You want a wide plateau, not a narrow peak.
The test perturbs each of V5’s frozen parameters ±2 steps from its default, re-runs the full pipeline each time, and measures what happens.
What “Good” Looks Like
±1 neighborhood around the baseline should keep at least 80% of baseline Sharpe
The Sharpe-vs-parameter curve should look smooth, not spiky
No single parameter should make or break the engine
The Results
Sensitivity ranking (worst to best):

Minimum neighborhood stability across all parameters: 96.1%. Required: 80%.
What To Take Away
Every parameter is on a smooth plateau. The most sensitive knob is minVotes (the number of votes required to confirm a regime), and even that holds 96.1% of baseline Sharpe at ±1, and only drops ~18% at the edge of ±2.
Translation: if my knobs were slightly wrong.. maybe minVotes should have been 11 or 13 instead of 12, the engine would still work.
This is the test I was most worried about before running the suite. It came back cleaner than any of the other five.
Test 5: New Input Impact
(No chart; this test produces a results table rather than a visualization.)
Why This Test Matters
This is the “am I missing something obvious?” test. The engine has 25+ voter inputs. There are hundreds of macro series out there. Are any of them adding signal I’m not picking up?
The way to find out: take each candidate, add it to the stack, re-run the engine, and see if the composite score (a blend of Sharpe + Calmar + drawdown) improves by a meaningful margin without degrading the OOS ratio.
What “Good” Looks Like
A candidate should only be promoted if it improves the composite score by a meaningful margin (> 0.005) AND doesn’t degrade out-of-sample performance. “Meaningful margin” matters because you can always add inputs and squeeze the in-sample result up by noise. What you care about is whether it still holds OOS.
The Results
Current status: no candidates under active evaluation. The v05 baseline (25+ voters) is the locked production stack.
The test itself is still alive.. there’s an equivalence guard that runs at startup to confirm the test’s internal pipeline still matches production behavior exactly (this protects against the engine silently drifting from what the test thinks it’s testing). That guard passed (5,860 days checked, 0 differences).
Previous candidates: DFII10, IG_OAS, T10Y3M were pruned after evaluation.. none showed enough lift to justify adding complexity. If I ever find a candidate worth testing, the framework is ready.
What To Take Away
The voter stack is stable and the guardrails around it work. No obvious free money is being left on the table.
More inputs is almost always worse in systematic trading, not better. Every voter you add is another knob that can drift, another data feed that can break, another thing to maintain. The bar for promotion is deliberately high.
Test 6: Synthetic Price Simulation (SPS)
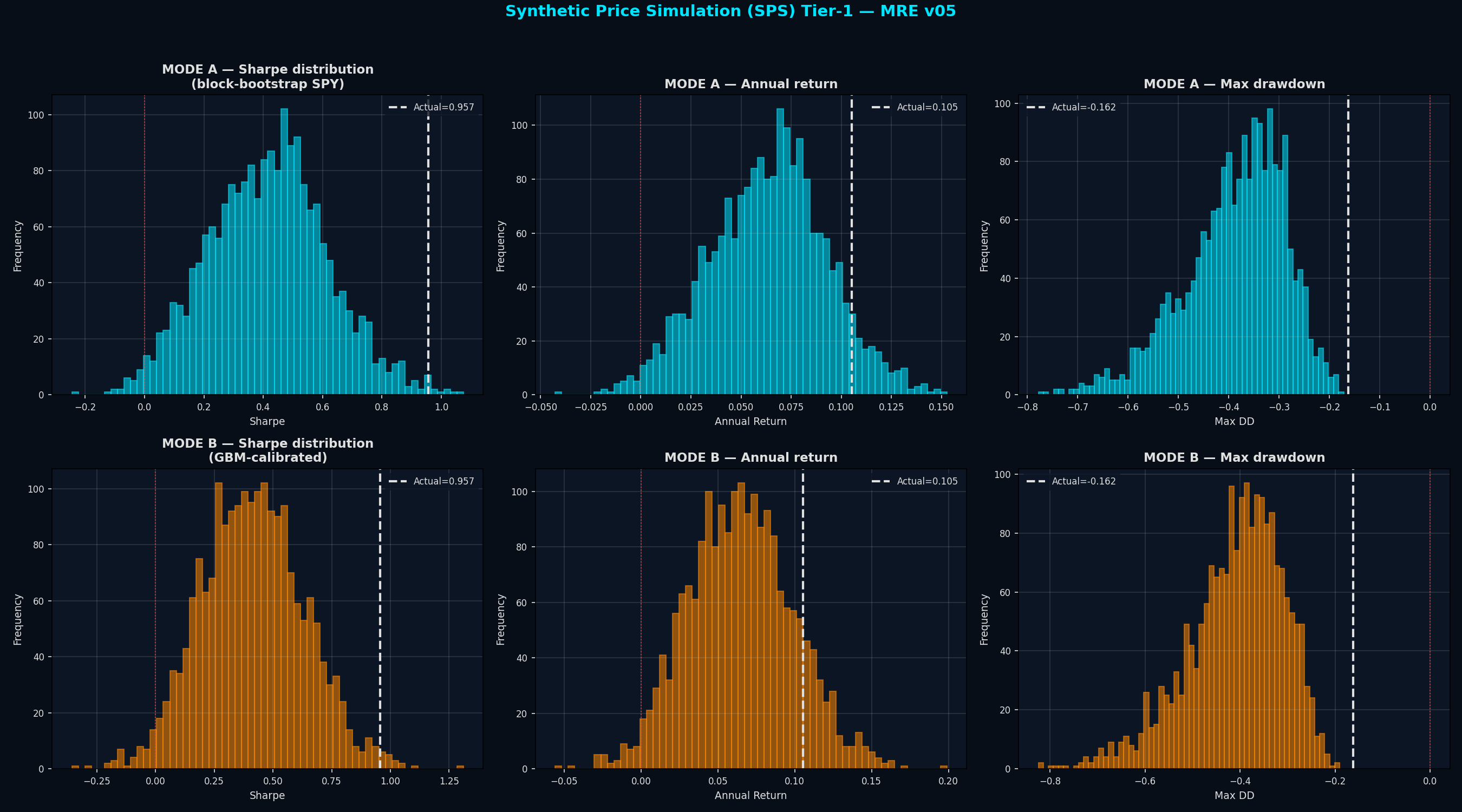
Why This Test Matters
This is the hardest test in the suite, and the one I was most excited to run.
Tests 1–5 all use real SPY data. But real SPY is one particular path through history. What if SPY had traced a different path? The 2008 crash could have been 30% instead of 57%. COVID could have recovered more slowly. The 2020s could have been a chop market instead of a bull run.
SPS asks: if SPY had walked a statistically-similar but different path, would the engine still have produced positive results?
I generated 2,000 synthetic SPY paths two different ways:
Mode A: Block-bootstrap. Chop the real SPY daily returns into 20-day blocks, shuffle them into new sequences. This preserves volatility clustering (ugly weeks stay ugly) and fat tails (crashes are still part of the data).
Mode B: GBM-calibrated. Generate clean Gaussian paths with the same average return and volatility as SPY, but no vol clustering, no fat tails, no autocorrelation. A “smoothed” version of SPY.
Then I hold the engine’s actual position schedule fixed and re-apply it to each synthetic path. 4,000 simulations total. The actual (real-SPY) result gets placed inside the distribution of all 4,000.
Important distinction: Test 2 (Monte Carlo) shuffles strategy returns. Test 6 shuffles the underlying SPY path and lets the engine’s positioning schedule take its shot at it. They test completely different failure modes.
What “Good” Looks Like
The 5th percentile Sharpe should be positive under both modes. The actual result should sit inside the bulk of the distribution (not wildly above or below).
Best case: the engine produces positive results across both fat-tailed and smoothed versions of SPY. That means it isn’t depending on one specific path, one specific crash, one specific recovery.
The Results
Mode A — Block-bootstrap (fat tails + vol clustering preserved):
Actual Sharpe 0.957 sits at the 99.6th percentile of 2,000 sims
5th percentile Sharpe: +0.088 (positive: pass)
Median sim Sharpe: +0.419
Actual max DD (−16.2%) is better than 100% of simulated paths
Mode B — GBM (Gaussian, clean):
Actual Sharpe 0.957 at the 99.1st percentile
5th percentile Sharpe: +0.069 (positive: pass)
Median sim Sharpe: +0.412
Verdict: PASS under both modes.
What To Take Away
The engine’s positioning schedule is wildly robust to the specific path SPY took. Under fat-tailed bootstrap and under smoothed Gaussian paths, the real-world result sits at the 99th percentile of 2,000 simulations, meaning the engine’s schedule is exploiting real structure in the position of long vs. flat days, not riding a lucky SPY path.
The p5 results are also the reason we test. Even in the unluckiest 5% of the 2,000 paths, the engine still produces a positive Sharpe. That’s the test failing to find a synthetic SPY path where the engine collapses.
What All Six Tests Say Together
Here’s the honest summary:
OOS holdout: frozen parameters hold up on unseen data (actually improved)
Monte Carlo: result isn’t sequence-dependent
Regime + Crisis: engine is decisive, doesn’t whipsaw, handled the big crises cleanly
Parameter Sensitivity: every knob sits on a smooth plateau, not a cliff
Input Impact: the 25+ voter stack is locked, no candidates worth adding
SPS: engine doesn’t depend on SPY’s specific historical path
If any one of these had failed, it would have been an interesting puzzle. If three had failed, I’d be rebuilding the engine.
Zero failed. That’s about as clean as a forward-test suite gets.
Does That Mean It Will Work Forever?
No. Obviously not. No test can tell you the future.
What these six tests can tell you is: the engine you’ve built is not fooling you. It’s not curve-fit. It’s not sequence-lucky. It’s not missing something obvious. It didn’t just catch a favorable path through history.
Those are huge claims. They don’t guarantee forward performance. Markets evolve. Central banks invent new tools. Correlations break. That’s fine. The engine was never a crystal ball. It’s a seatbelt.
The question this suite answers isn’t “will this work tomorrow?” The question is “have I built something that deserves to be trusted?“
Based on six independent probes, the answer is yes.
Survival is alpha. Go use it.
— Durden out.
✊🧼
Want the live dashboards behind these insights?
Subscribe on Substack Free subscribers get research updates. Paid subscribers get live macro tools + signal alerts.